You are given an m x n binary matrix mat of 1's (representing soldiers) and 0's (representing civilians). The soldiers are positioned in front of the civilians. That is, all the 1's will appear to the left of all the 0's in each row.
A row i is weaker than a row j if one of the following is true:
The number of soldiers in row i is less than the number of soldiers in row j.
Both rows have the same number of soldiers and i < j.
Return the indices of thekweakest rows in the matrix ordered from weakest to strongest.
Example 1:
<pre>Input: mat =
[[1,1,0,0,0],
[1,1,1,1,0],
[1,0,0,0,0],
[1,1,0,0,0],
[1,1,1,1,1]],
k = 3
Output: [2,0,3]
Explanation:
The number of soldiers in each row is:
Row 0: 2
Row 1: 4
Row 2: 1
Row 3: 2
Row 4: 5
The rows ordered from weakest to strongest are [2,0,3,1,4].
</pre>
Example 2:
<pre>Input: mat =
[[1,0,0,0],
[1,1,1,1],
[1,0,0,0],
[1,0,0,0]],
k = 2
Output: [0,2]
Explanation:
The number of soldiers in each row is:
Row 0: 1
Row 1: 4
Row 2: 1
Row 3: 1
The rows ordered from weakest to strongest are [0,2,3,1].
</pre>
defkWeakestRows(self, mat: List[List[int]], k: int) -> List[int]: nums_soldiers = [(sum(mat[i]), i) for i inrange(len(mat))] res = [] for i inrange(len(nums_soldiers)): if i < k: heappush(res, (-nums_soldiers[i][0], -nums_soldiers[i][1])) # put into the heap if weaker elif -nums_soldiers[i][0] > res[0][0] or \ (nums_soldiers[i][0] == res[0][0] and -nums_soldiers[i][1] > res[0][1]): heapreplace(res, (-nums_soldiers[i][0], -nums_soldiers[i][1])) res.sort(key=lambda x: (-x[0], -x[1])) return [-res[i][1] for i inrange(len(res))]
You have a 2-D grid of size m x n representing a box, and you have n balls. The box is open on the top and bottom sides.
Each cell in the box has a diagonal board spanning two corners of the cell that can redirect a ball to the right or to the left.
A board that redirects the ball to the right spans the top-left corner to the bottom-right corner and is represented in the grid as 1.
A board that redirects the ball to the left spans the top-right corner to the bottom-left corner and is represented in the grid as -1.
We drop one ball at the top of each column of the box. Each ball can get stuck in the box or fall out of the bottom. A ball gets stuck if it hits a "V" shaped pattern between two boards or if a board redirects the ball into either wall of the box.
Return an arrayanswerof sizenwhereanswer[i]is the column that the ball falls out of at the bottom after dropping the ball from thei<sup>th</sup>column at the top, or -1if the ball gets stuck in the box.
Example 1:
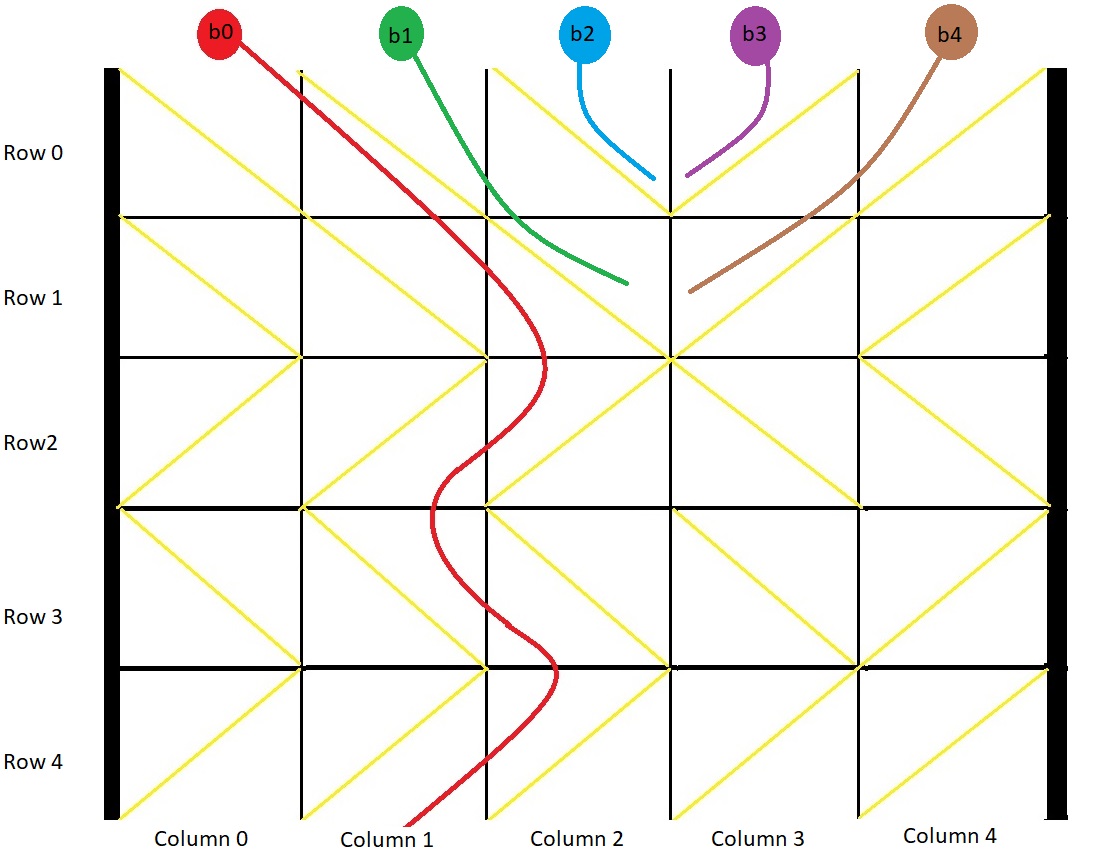
<pre>Input: grid = [[1,1,1,-1,-1],[1,1,1,-1,-1],[-1,-1,-1,1,1],[1,1,1,1,-1],[-1,-1,-1,-1,-1]]
Output: [1,-1,-1,-1,-1]
Explanation: This example is shown in the photo.
Ball b0 is dropped at column 0 and falls out of the box at column 1.
Ball b1 is dropped at column 1 and will get stuck in the box between column 2 and 3 and row 1.
Ball b2 is dropped at column 2 and will get stuck on the box between column 2 and 3 and row 0.
Ball b3 is dropped at column 3 and will get stuck on the box between column 2 and 3 and row 0.
Ball b4 is dropped at column 4 and will get stuck on the box between column 2 and 3 and row 1.
</pre>
Example 2:
<pre>Input: grid = [[-1]]
Output: [-1]
Explanation: The ball gets stuck against the left wall.
</pre>