Strings s1 and s2 are k-similar (for some non-negative integer k) if we can swap the positions of two letters in s1 exactly k times so that the resulting string equals s2.
Given two anagrams s1 and s2, return the smallest k for which s1 and s2 are k-similar.
Example 1:
Input: s1 = “ab”, s2 = “ba” Output: 1
Example 2:
Input: s1 = “abc”, s2 = “bca” Output: 2
Constraints:
1 <= s1.length <= 20s2.length == s1.length s1 and s2 contain only lowercase letters from the set {'a', 'b', 'c', 'd', 'e', 'f'}.
s2 is an anagram of s1.
Given two strings s and goal, return trueif you can swap two letters insso the result is equal togoal, otherwise, returnfalse.
Swapping letters is defined as taking two indices i and j (0-indexed) such that i != j and swapping the characters at s[i] and s[j].
For example, swapping at indices 0 and 2 in "abcd" results in "cbad".
Example 1:
Input: s = “ab”, goal = “ba” Output: true Explanation: You can swap s[0] = ‘a’ and s[1] = ‘b’ to get “ba”, which is equal to goal.
Example 2:
Input: s = “ab”, goal = “ab” Output: false Explanation: The only letters you can swap are s[0] = ‘a’ and s[1] = ‘b’, which results in “ba” != goal.
Example 3:
Input: s = “aa”, goal = “aa” Output: true Explanation: You can swap s[0] = ‘a’ and s[1] = ‘a’ to get “aa”, which is equal to goal.
Constraints:1 <= s.length, goal.length <= 2 * 10<sup>4</sup> * s and goal consist of lowercase letters.
题目大意:
给定两字符串,交换一次使得他们相等
解题思路:
三种情况: 长度不等,完全相等(若至少有一个重复,即满足题意),两次不同
解题步骤:
N/A
注意事项:
三种情况: 长度不等,完全相等,两次不同
Python代码:
1 2 3 4 5 6 7
defbuddyStrings(self, s: str, goal: str) -> bool: if len(s) != len(goal): returnFalse if s == goal and len(set(s)) < len(goal): # any dups returnTrue diff = [(a, b) for a, b in zip(s, goal) if a != b] returnTrueif len(diff) == 2and diff[0] == diff[1][::-1] elseFalse
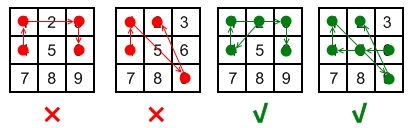
Android devices have a special lock screen with a 3 x 3 grid of dots. Users can set an “unlock pattern” by connecting the dots in a specific sequence, forming a series of joined line segments where each segment’s endpoints are two consecutive dots in the sequence. A sequence of k dots is a valid unlock pattern if both of the following are true:
All the dots in the sequence are distinct.
If the line segment connecting two consecutive dots in the sequence passes through the center of any other dot, the other dot must have previously appeared in the sequence. No jumps through the center non-selected dots are allowed. For example, connecting dots 2 and 9 without dots 5 or 6 appearing beforehand is valid because the line from dot 2 to dot 9 does not pass through the center of either dot 5 or 6.
However, connecting dots 1 and 3 without dot 2 appearing beforehand is invalid because the line from dot 1 to dot 3 passes through the center of dot 2.
Here are some example valid and invalid unlock patterns:
The 1st pattern [4,1,3,6] is invalid because the line connecting dots 1 and 3 pass through dot 2, but dot 2 did not previously appear in the sequence.
The 2nd pattern [4,1,9,2] is invalid because the line connecting dots 1 and 9 pass through dot 5, but dot 5 did not previously appear in the sequence. The 3rd pattern [2,4,1,3,6] is valid because it follows the conditions. The line connecting dots 1 and 3 meets the condition because dot 2 previously appeared in the sequence.
The 4th pattern [6,5,4,1,9,2] is valid because it follows the conditions. The line connecting dots 1 and 9 meets the condition because dot 5 previously appeared in the sequence.
Given two integers m and n, return the number of unique and valid unlock patterns of the Android grid lock screen that consist of at leastmkeys and at mostnkeys.
Two unlock patterns are considered unique if there is a dot in one sequence that is not in the other, or the order of the dots is different.
defdfs(self, num, m, n, visited): if num in visited: return0 visited.add(num) if len(visited) == n: visited.remove(num) # remember return1 res = 0 if len(visited) >= m: res += 1 for next_num in range(1, 10): if (num, next_num) in JUMP_KEYS and JUMP_KEYS[(num, next_num)] notin visited: continue res += self.dfs(next_num, m, n, visited) visited.remove(num) return res
Given a file and assume that you can only read the file using a given method read4, implement a method read to read n characters. Your method read may be called multiple times.
Method read4:
The API read4 reads four consecutive characters from file, then writes those characters into the buffer array buf4.
The return value is the number of actual characters read.
Note that read4() has its own file pointer, much like FILE *fp in C.
Definition of read4:
Parameter: char[] buf4 Returns: int
buf4[] is a destination, not a source. The results from read4 will be copied to buf4[].
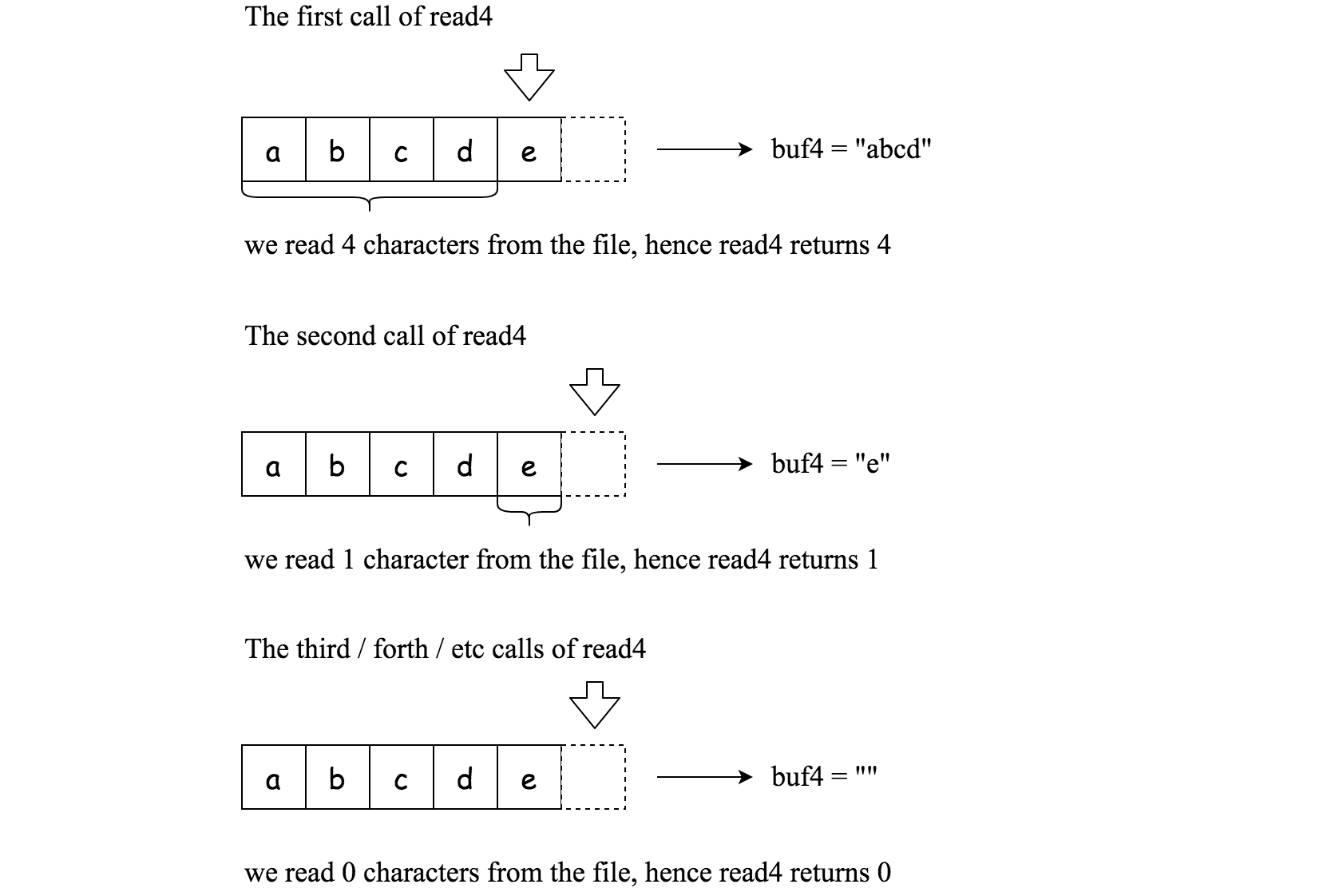
Below is a high-level example of how read4 works:
File file(“abcde"); // File is "abcde", initially file pointer (fp) points to 'a'
char[] buf4 = new char[4]; // Create buffer with enough space to store characters
read4(buf4); // read4 returns 4\. Now buf4 = "abcd", fp points to 'e'
read4(buf4); // read4 returns 1\. Now buf4 = "e", fp points to end of file
read4(buf4); // read4 returns 0\. Now buf4 = "", fp points to end of file
Method read:
By using the read4 method, implement the method read that reads n characters from file and store it in the buffer array buf. Consider that you cannot manipulate file directly.
The return value is the number of actual characters read.
Definition of read:
Parameters: char[] buf, int n Returns: int
buf[] is a destination, not a source. You will need to write the results to buf[].
Note:
Consider that you cannot manipulate the file directly. The file is only accessible for read4 but not for read.
The read function may be called multiple times. Please remember to RESET your class variables declared in Solution, as static/class variables are persisted across multiple test cases. Please see here for more details.
You may assume the destination buffer array, buf, is guaranteed to have enough space for storing n characters. It is guaranteed that in a given test case the same buffer buf is called by read.
Example 1:
Input: file = “abc”, queries = [1,2,1] Output: [1,2,0] Explanation: The test case represents the following scenario: File file(“abc”); Solution sol; sol.read(buf, 1); // After calling your read method, buf should contain “a”. We read a total of 1 character from the file, so return 1. sol.read(buf, 2); // Now buf should contain “bc”. We read a total of 2 characters from the file, so return 2. sol.read(buf, 1); // We have reached the end of file, no more characters can be read. So return 0. Assume buf is allocated and guaranteed to have enough space for storing all characters from the file.
Example 2:
Input: file = “abc”, queries = [4,1] Output: [3,0] Explanation: The test case represents the following scenario: File file(“abc”); Solution sol; sol.read(buf, 4); // After calling your read method, buf should contain “abc”. We read a total of 3 characters from the file, so return 3. sol.read(buf, 1); // We have reached the end of file, no more characters can be read. So return 0.
Constraints:1 <= file.length <= 500 file consist of English letters and digits.
1 <= queries.length <= 10 * 1 <= queries[i] <= 500
题目大意:
题意类似于LeetCode 157 Read N Characters Given Read4,但此题唯一的区别是这个新的API: def read(self, buf, n)会被调用多次
Given a file and assume that you can only read the file using a given method read4, implement a method to read n characters.
Method read4:
The API read4 reads four consecutive characters from file, then writes those characters into the buffer array buf4.
The return value is the number of actual characters read.
Note that read4() has its own file pointer, much like FILE *fp in C.
Definition of read4:
Parameter: char[] buf4 Returns: int
buf4[] is a destination, not a source. The results from read4 will be copied to buf4[].
Below is a high-level example of how read4 works:
File file(“abcde"); // File is "abcde", initially file pointer (fp) points to 'a'
char[] buf4 = new char[4]; // Create buffer with enough space to store characters
read4(buf4); // read4 returns 4\. Now buf4 = "abcd", fp points to 'e'
read4(buf4); // read4 returns 1\. Now buf4 = "e", fp points to end of file
read4(buf4); // read4 returns 0\. Now buf4 = "", fp points to end of file
Method read:
By using the read4 method, implement the method read that reads n characters from file and store it in the buffer array buf. Consider that you cannot manipulate file directly.
The return value is the number of actual characters read.
Definition of read:
Parameters: char[] buf, int n Returns: int
buf[] is a destination, not a source. You will need to write the results to buf[].
Note:
Consider that you cannot manipulate the file directly. The file is only accessible for read4 but not for read.
The read function will only be called once for each test case. You may assume the destination buffer array, buf, is guaranteed to have enough space for storing n characters.
Example 1:
Input: file = “abc”, n = 4 Output: 3 Explanation: After calling your read method, buf should contain “abc”. We read a total of 3 characters from the file, so return 3. Note that “abc” is the file’s content, not buf. buf is the destination buffer that you will have to write the results to.
Example 2:
Input: file = “abcde”, n = 5 Output: 5 Explanation: After calling your read method, buf should contain “abcde”. We read a total of 5 characters from the file, so return 5.
Example 3:
Input: file = “abcdABCD1234”, n = 12 Output: 12 Explanation: After calling your read method, buf should contain “abcdABCD1234”. We read a total of 12 characters from the file, so return 12.
Constraints:1 <= file.length <= 500 file consist of English letters and digits.
1 <= n <= 1000
题目大意:
Karat题,有一个函数read4,如此调用
1 2
buf4 = [' '] * 4 count = read4(buf4)
buf4是填充后的结果,是一个大小为4的char list count是buf4的有数据的实际大小(4或更小,取决于是否文件最后一段是否不够4)
现在要实现这个函数
1
def read(self, buf, n)
buf是字符列表,n是想要读取文件的大小,返回值为n或者更小,取决于是否文件大小是否小于n
解题思路:
N/A
解题步骤:
N/A
注意事项:
若count为0,跳出循环
Python代码:
1 2 3 4 5 6 7 8 9 10 11
defread(self, buf, n): i = 0 while i < n: buf4 = [' '] * 4 count = read4(buf4) ifnot count: # avoid dead loop break count = min(count, n - i) buf[i:] = buf4 i += count return i