You are given an integer array nums. You are initially positioned at the array's first index, and each element in the array represents your maximum jump length at that position.
Return trueif you can reach the last index, orfalseotherwise.
Example 1:
<pre>Input: nums = [2,3,1,1,4]
Output: true
Explanation: Jump 1 step from index 0 to 1, then 3 steps to the last index.
</pre>
Example 2:
<pre>Input: nums = [3,2,1,0,4]
Output: false
Explanation: You will always arrive at index 3 no matter what. Its maximum jump length is 0, which makes it impossible to reach the last index.
</pre>
Constraints:
1 <= nums.length <= 10<sup>4</sup>
0 <= nums[i] <= 10<sup>5</sup>
</div>
题目大意:
N/A
解题思路:
BFS,但不需要用queue
解题步骤:
N/A
注意事项:
参考Jump game II,区别在于如果i <= end才更新,
返回next_end要大于等于(可以cover)最后一个元素下标
Python代码:
1 2 3 4 5 6 7 8
defcanJump(self, nums: List[int]) -> bool: end, next_end = 0, 0 for i inrange(len(nums) - 1): if i <= end: next_end = max(next_end, i + nums[i]) # 4 if i == end: # end = next_end # 8 return next_end >= len(nums) - 1
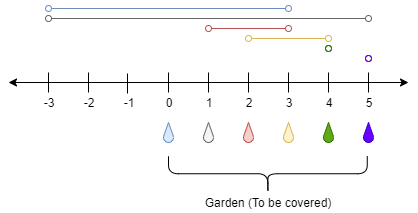
There is a one-dimensional garden on the x-axis. The garden starts at the point 0 and ends at the point n. (i.e The length of the garden is n).
There are n + 1 taps located at points [0, 1, ..., n] in the garden.
Given an integer n and an integer array ranges of length n + 1 where ranges[i] (0-indexed) means the i-th tap can water the area [i - ranges[i], i + ranges[i]] if it was open.
Return the minimum number of taps that should be open to water the whole garden, If the garden cannot be watered return -1.
Example 1:
<pre>Input: n = 5, ranges = [3,4,1,1,0,0]
Output: 1
Explanation: The tap at point 0 can cover the interval [-3,3]
The tap at point 1 can cover the interval [-3,5]
The tap at point 2 can cover the interval [1,3]
The tap at point 3 can cover the interval [2,4]
The tap at point 4 can cover the interval [4,4]
The tap at point 5 can cover the interval [5,5]
Opening Only the second tap will water the whole garden [0,5]
</pre>
Example 2:
<pre>Input: n = 3, ranges = [0,0,0,0]
Output: -1
Explanation: Even if you activate all the four taps you cannot water the whole garden.
</pre>
Example 3:
<pre>Input: n = 7, ranges = [1,2,1,0,2,1,0,1]
Output: 3
</pre>
Example 4:
<pre>Input: n = 8, ranges = [4,0,0,0,0,0,0,0,4]
Output: 2
</pre>
Example 5:
<pre>Input: n = 8, ranges = [4,0,0,0,4,0,0,0,4]
Output: 1
</pre>
defminTaps(self, n: int, ranges: List[int]) -> int: end, next_end, res = 0, 0, 0 nums = [0] * len(ranges) for i inrange(len(ranges)): if i - ranges[i] <= 0: nums[0] = max(nums[0], ranges[i] + i) else: nums[i - ranges[i]] = max(nums[i - ranges[i]], ranges[i] * 2)
for i inrange(len(nums) - 1): # remember if i <= end: # -3 <= 0 next_end = max(next_end, i + nums[i]) # 3 if i == end: end = next_end res += 1 return res if next_end >= len(nums) - 1else -1
An underground railway system is keeping track of customer travel times between different stations. They are using this data to calculate the average time it takes to travel from one station to another.
Implement the UndergroundSystem class:
void checkIn(int id, string stationName, int t)
A customer with a card ID equal to id, checks in at the station stationName at time t.
A customer can only be checked into one place at a time.
void checkOut(int id, string stationName, int t)
A customer with a card ID equal to id, checks out from the station stationName at time t.
Returns the average time it takes to travel from startStation to endStation.
The average time is computed from all the previous traveling times from startStation to endStation that happened directly, meaning a check in at startStation followed by a check out from endStation.
The time it takes to travel from startStation to endStationmay be different from the time it takes to travel from endStation to startStation.
There will be at least one customer that has traveled from startStation to endStation before getAverageTime is called.
You may assume all calls to the checkIn and checkOut methods are consistent. If a customer checks in at time t<sub>1</sub> then checks out at time t<sub>2</sub>, then t<sub>1</sub> < t<sub>2</sub>. All events happen in chronological order.
You are given a 0-indexed array of positive integers w where w[i] describes the weight of the i<sup>th</sup> index.
You need to implement the function pickIndex(), which randomly picks an index in the range [0, w.length - 1] (inclusive) and returns it. The probability of picking an index i is w[i] / sum(w).
For example, if w = [1, 3], the probability of picking index 0 is 1 / (1 + 3) = 0.25 (i.e., 25%), and the probability of picking index 1 is 3 / (1 + 3) = 0.75 (i.e., 75%).
Explanation
Solution solution = new Solution([1]);
solution.pickIndex(); // return 0. The only option is to return 0 since there is only one element in w.
</pre>
Explanation
Solution solution = new Solution([1, 3]);
solution.pickIndex(); // return 1. It is returning the second element (index = 1) that has a probability of 3/4.
solution.pickIndex(); // return 1
solution.pickIndex(); // return 1
solution.pickIndex(); // return 1
solution.pickIndex(); // return 0. It is returning the first element (index = 0) that has a probability of 1/4.
Since this is a randomization problem, multiple answers are allowed.
All of the following outputs can be considered correct:
[null,1,1,1,1,0]
[null,1,1,1,1,1]
[null,1,1,1,0,0]
[null,1,1,1,0,1]
[null,1,0,1,0,0]
......
and so on.
</pre>
Constraints:
1 <= w.length <= 10<sup>4</sup>
1 <= w[i] <= 10<sup>5</sup>
pickIndex will be called at most 10<sup>4</sup> times.
<pre>Input: strs = ["dog","racecar","car"]
Output: ""
Explanation: There is no common prefix among the input strings.
</pre>
Constraints:
1 <= strs.length <= 200
0 <= strs[i].length <= 200
strs[i] consists of only lower-case English letters.
</div>
题目大意:
字符串列表的最长前缀
算法思路:
N/A
注意事项:
求最小值len初始值用最大值而不是0
char = strs[0][i]而不是char = strs[i]
Python代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
deflongestCommonPrefix(self, strs: List[str]) -> str: min_len, res = sys.maxsize, '' for s in strs: min_len = min(min_len, len(s)) for i inrange(min_len): char = strs[0][i] same_char = True for j inrange(1, len(strs)): if char != strs[j][i]: same_char = False break ifnot same_char: break res += char return res