if nums[end] == target: return end elif nums[start] == target: return start else: return-1
Python代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
deflast_position(self, nums: List[int], target: int) -> int: ifnot nums: return-1 start, end = 0, len(nums) - 1 while start + 1 < end: mid = start + (end - start) // 2 if target < nums[mid]: end = mid elif target > nums[mid]: start = mid else: # Depends on the target on the right side or left side. For fist pos, use end = mid start = mid
if nums[end] == target: return end elif nums[start] == target: return start else: return-1
Python代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
deffirst_position(self, nums: List[int], target: int) -> int: ifnot nums: return-1 start, end = 0, len(nums) - 1 while start + 1 < end: mid = start + (end - start) // 2 if target < nums[mid]: end = mid elif target > nums[mid]: start = mid else: end = mid
if nums[start] == target: return start elif nums[end] == target: return end else: return-1
Python代码:
如果是smaller_or_equal_position,Line 13和15取等号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
defsmaller_position(self, nums: List[int], target: int) -> int: ifnot nums: return-1 start, end = 0, len(nums) - 1 while start + 1 < end: mid = start + (end - start) // 2 if target > nums[mid]: start = mid elif target < nums[mid]: end = mid else: end = mid if nums[end] < target: # nums[end] <= target for smaller_or_equal_position return end if nums[start] < target: # nums[start] < target for smaller_or_equal_position return start return-1
Python代码:
如果是greater_or_equal_position,Line 13和15取等号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
defgreater_position(self, nums: List[int], target: int) -> int: ifnot nums: return-1 start, end = 0, len(nums) - 1 while start + 1 < end: mid = start + (end - start) // 2 if target > nums[mid]: start = mid elif target < nums[mid]: end = mid else: start = mid if nums[start] > target: # nums[start] >= target for greater_or_equal_position return start if nums[end] > target: # nums[end] >= target for greater_or_equal_position return end return-1
找峰值
注意事项:
判断mid+1的元素不越界
最后返回start和end之中较大者
Python代码:
1 2 3 4 5 6 7 8 9 10 11
deffind_peak(self, nums: List[int]) -> int: ifnot nums: return-1 start, end = 0, len(nums) - 1 while start + 1 < end: mid = start + (end - start) // 2 if mid + 1 <= end and nums[mid] < nums[mid + 1]: start = mid else: end = mid return start if nums[start] > nums[end] else end
In an infinite chess board with coordinates from -infinity to +infinity, you have a knight at square [0, 0].
A knight has 8 possible moves it can make, as illustrated below. Each move is two squares in a cardinal direction, then one square in an orthogonal direction.
Return the minimum number of steps needed to move the knight to the square [x, y]. It is guaranteed the answer exists.
Example 1:
Input: x = 2, y = 1
Output: 1
Explanation: [0, 0] → [2, 1]
Because x and y are constrained to be in range[-300, 300], we can use BFS to find the minimum steps needed to reach target(x, y). Furthermore, we can only consider the case that x >=0 && y >=0 since the chess board is symmetric. The bfs implementation is pretty straightforward. There are two important points you need to be careful with.
Pruning. We can limit the search dimension within 310 * 310. Any moves that lead to a position that is outside this box will not yield an optimal result.
2. Initially, you used a Set of type int[] to track visited positions. This caused TLE because you didn’t overwrite the hashCode and equals methods for int[]. As a result, Set uses the default hashCode and equals method when checking if an element is already in the set. For equals(), The default implementation provided by the JDK is based on memory location — two objects are equal if and only if they are stored in the same memory address. For a comprehensive reading, refer to https://dzone.com/articles/working-with-hashcode-and-equals-in-java
for direction in directions: neighbor = (node[0] + direction[0], node[1] + direction[1]) if neighbor in visited: continue queue.append(neighbor) visited.add(neighbor) distance[neighbor] = distance[node] + 1
Given two words (beginWord and endWord), and a dictionary’s word list, find the length of shortest transformation sequence from beginWord to endWord, such that:
1. Only one letter can be changed at a time. 2. Each transformed word must exist in the word list.
Note:
Return 0 if there is no such transformation sequence.
All words have the same length. All words contain only lowercase alphabetic characters.
You may assume no duplicates in the word list. You may assume beginWord and endWord are non-empty and are not the same.
defbfs(self, beginWord, endWord, dict, visited): queue = deque([beginWord]) visited.add(beginWord) while queue: word = queue.popleft() if word == endWord: return dict[word]
neighbors = self.get_next_words(word, dict) for neighbor in neighbors: if neighbor notin visited: queue.append(neighbor) visited.add(neighbor) dict[neighbor] = dict[word] + 1
return0
defget_next_words(self, word, dict): res = [] for i in range(len(word)): for c in string.ascii_lowercase: # or use 'abcdefghijklmnopqrstuvwxyz' if c == word[i]: continue new_word = word[:i] + c + word[i + 1:] if new_word in dict: res.append(new_word) return res
publicintladderLength(String beginWord, String endWord, List<String> wordList){ // This is a dict and also keeps track of distance Map<String, Integer> dict = getDict(wordList); // Make sure endWord is in the dict and can be the next word //dict.put(endWord, 0); dict.put(beginWord, 1); Set<String> visited = new HashSet<>(); Queue<String> q = new LinkedList<>(); q.offer(beginWord); visited.add(beginWord); while(!q.isEmpty()) { String word = q.poll(); if(endWord.equals(word)) return dict.get(word); List<String> nextWords = getNextWords(word, dict); for(String s : nextWords) { if(visited.contains(s)) continue; q.offer(s); visited.add(s); dict.put(s, dict.get(word) + 1); } } return0; }
forward_queue, backward_queue = deque([beginWord]), deque([endWord]) forward_visited, backward_visited = set([beginWord]), set([endWord]) while forward_queue and backward_queue: total_dis = self.bfs_from_start_or_end(graph, forward_queue, forward_distance, backward_distance) if total_dis > 0: return total_dis total_dis = self.bfs_from_start_or_end(graph, backward_queue, backward_distance, forward_distance) if total_dis > 0: return total_dis return0
defbfs_from_start_or_end(self, graph, queue, distance, target_dict): word = queue.popleft() if word in target_dict and target_dict[word] > 0: # the forward distance has all words initially return distance[word] + target_dict[word]
neighbors = graph[word] for neighbor in neighbors: #if neighbor in visited: if neighbor in distance: continue queue.append(neighbor) # visited.add(neighbor) distance[neighbor] = distance[word] + 1 return0
Serialization is the process of converting a data structure or object into a sequence of bits so that it can be stored in a file or memory buffer, or transmitted across a network connection link to be reconstructed later in the same or another computer environment.
Design an algorithm to serialize and deserialize a binary tree. There is no restriction on how your serialization/deserialization algorithm should work. You just need to ensure that a binary tree can be serialized to a string and this string can be deserialized to the original tree structure.
Example:
You may serialize the following tree:
1
/ \
2 3
/ \
4 5
as `"[1,2,3,null,null,4,5]"`
Clarification: The above format is the same as how LeetCode serializes a binary tree. You do not necessarily need to follow this format, so please be creative and come up with different approaches yourself.
Note: Do not use class member/global/static variables to store states. Your serialize and deserialize algorithms should be stateless.
题目大意:
序列化和反序列化二叉树。
Python解法
算法思路:
N/A
注意事项:
BFS解码,空节点也要入列,因为要转成#,且不让代码往下执行
难点是用#补充空节点,令每个非空节点必有左右儿子,这样解码就可以固定地每轮扫描两个。出列一个父节点,p扫描两个儿子且生成节点,若为#即空节点不入列,这和编码不同。主要因为编码的长度比节点数多,所以生成节点时,不需要再处理空节点。 Line 25 - 32有重复,这里放在一起方便理解,也可以封装成函数
Each node in the graph contains a val (int) and a list (List[Node]) of its neighbors.
class Node {
public int val;
public List neighbors;
}
Test case format:
For simplicity sake, each node’s value is the same as the node’s index (1-indexed). For example, the first node with val = 1, the second node with val = 2, and so on. The graph is represented in the test case using an adjacency list.
Adjacency list is a collection of unordered lists used to represent a finite graph. Each list describes the set of neighbors of a node in the graph.
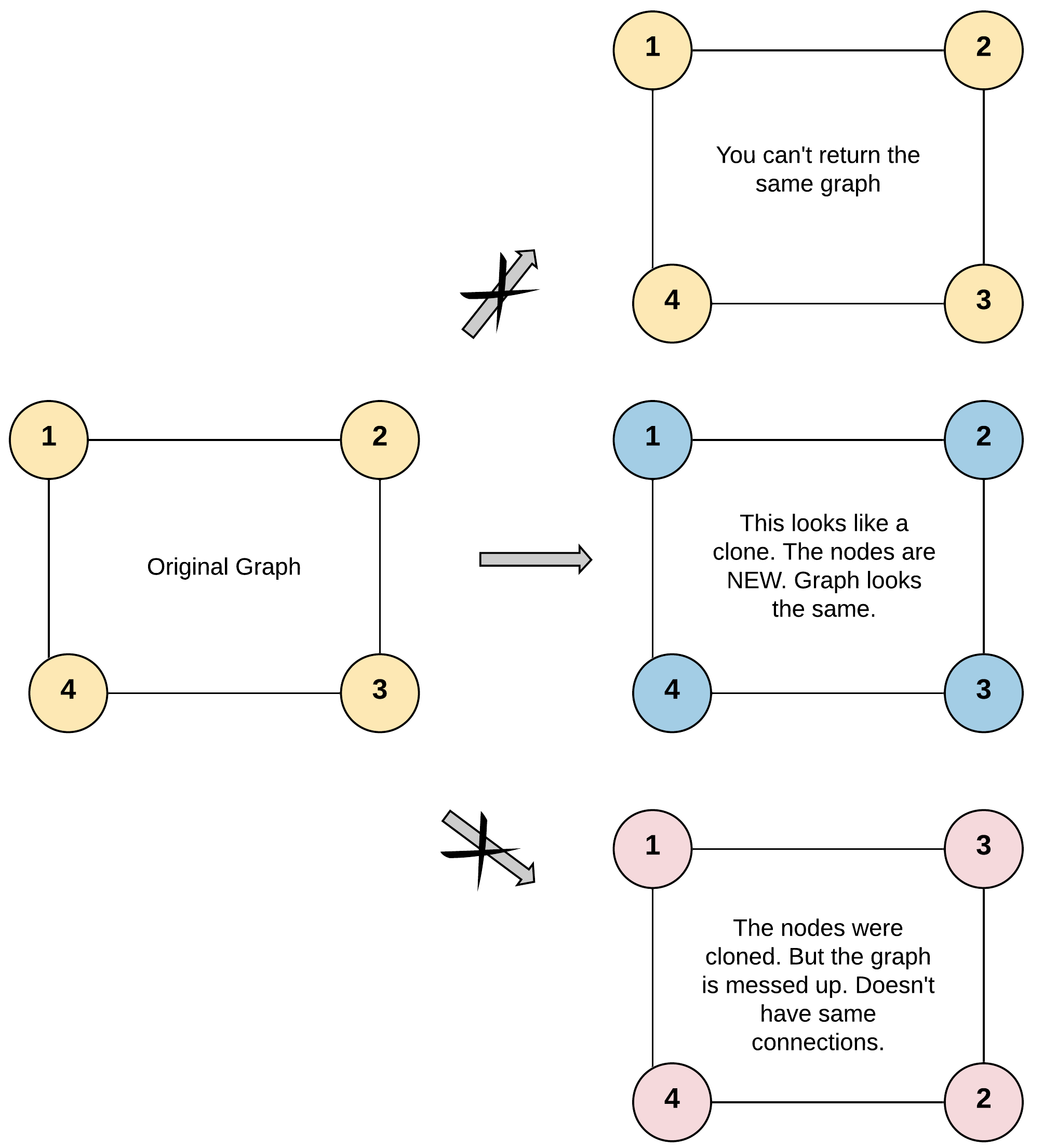
The given node will always be the first node with val = 1. You must return the copy of the given node as a reference to the cloned graph.
Example 1:
**Input:** adjList = [[2,4],[1,3],[2,4],[1,3]]
**Output:** [[2,4],[1,3],[2,4],[1,3]]
**Explanation:** There are 4 nodes in the graph.
1st node (val = 1)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
2nd node (val = 2)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
3rd node (val = 3)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
4th node (val = 4)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
Example 2:
**Input:** adjList = [[]]
**Output:** [[]]
**Explanation:** Note that the input contains one empty list. The graph consists of only one node with val = 1 and it does not have any neighbors.
Example 3:
**Input:** adjList = []
**Output:** []
**Explanation:** This an empty graph, it does not have any nodes.
defcloneGraph(self, node: 'Node') -> 'Node': ifnot node: returnNone di = {} node_list = self.bfs(node) for n in node_list: di[n] = Node(n.val) for n in node_list: for n2 in n.neighbors: di[n].neighbors.append(di[n2]) return di[node]
defbfs(self, input): queue = deque([input]) visited = {input} # graph = collections.defaultdict(list) res = [] while queue: node = queue.popleft() # graph[node] = [] res.append(node) for neighbor in node.neighbors: if neighbor in visited: continue queue.append(neighbor) visited.add(neighbor) # graph[node].append(neighbor) return res
// another bfs3 method uses 3 steps, convert graph to adjacent list by bfs (flatten the graph), //clone vertices, clone edges publicvoidbfs3(UndirectedGraphNode node, HashMap<UndirectedGraphNode, UndirectedGraphNode> map){ ArrayList<UndirectedGraphNode> nodes = getNodes(node); // Copy vertices for(UndirectedGraphNode old : nodes) { UndirectedGraphNode newNode = new UndirectedGraphNode(old.label); map.put(old, newNode); } // Copy edges for(UndirectedGraphNode old : nodes) { for(UndirectedGraphNode neighbor : old.neighbors) { map.get(old).neighbors.add(map.get(neighbor)); } } }
public ArrayList<UndirectedGraphNode> getNodes(UndirectedGraphNode node){ Queue<UndirectedGraphNode> q = new LinkedList<>(); Set<UndirectedGraphNode> result = new HashSet<>(); q.offer(node); result.add(node); // Use result set so we can save the visited set while(!q.isEmpty()) { UndirectedGraphNode n = q.poll(); for(UndirectedGraphNode neighbor : n.neighbors) { if(result.contains(neighbor)) continue; q.offer(neighbor); result.add(neighbor); } } ArrayList<UndirectedGraphNode> reList = new ArrayList<UndirectedGraphNode>(); reList.addAll(result); return reList; }