


LeetCode 138 Copy List with Random Pointer
A linked list of length n is given such that each node contains an additional random pointer, which could point to any node in the list, or null.
Construct a deep copy of the list. The deep copy should consist of exactly n brand new nodes, where each new node has its value set to the value of its corresponding original node. Both the next and random pointer of the new nodes should point to new nodes in the copied list such that the pointers in the original list and copied list represent the same list state. None of the pointers in the new list should point to nodes in the original list.
For example, if there are two nodes X and Y in the original list, where X.random --> Y, then for the corresponding two nodes x and y in the copied list, x.random --> y.
Return the head of the copied linked list.
The linked list is represented in the input/output as a list of n nodes. Each node is represented as a pair of [val, random_index] where:
val: an integer representingNode.valrandom_index: the index of the node (range from0ton-1) that therandompointer points to, ornullif it does not point to any node.
Your code will only be given the head of the original linked list.
Example 1:
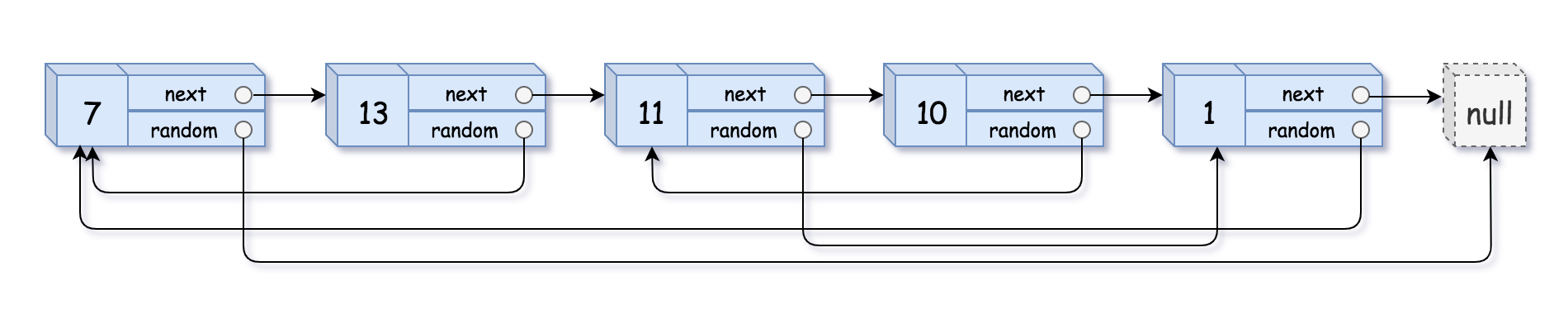
<pre>Input: head = [[7,null],[13,0],[11,4],[10,2],[1,0]] Output: [[7,null],[13,0],[11,4],[10,2],[1,0]] </pre>
Example 2:

<pre>Input: head = [[1,1],[2,1]] Output: [[1,1],[2,1]] </pre>
Example 3:

<pre>Input: head = [[3,null],[3,0],[3,null]] Output: [[3,null],[3,0],[3,null]] </pre>
Example 4:
<pre>Input: head = [] Output: [] Explanation: The given linked list is empty (null pointer), so return null. </pre>
Constraints:
0 <= n <= 1000-10000 <= Node.val <= 10000Node.randomisnullor is pointing to some node in the linked list.
题目大意:
复制含next和random的链表。
解题思路(推荐):
此法较容易实现。先复制next指针,然后利用HashMap存储旧新节点,来复制random指针。
注意事项:
- 复制next指针和Map中。clone题均用此法。
- Random指针不空才copy
- 加it = it.next,否则死循环
- 如果创建新Node用while it.next表示用它的父节点,否则某个field赋值如random用while it
Python代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def copyRandomList(self, head: 'Node') -> 'Node':
node_map = {}
fake_head, fake_head_copy = Node(0), Node(0)
fake_head.next = head
it, it_copy = fake_head, fake_head_copy
while it.next:
it_copy.next = Node(it.next.val)
node_map[it.next] = it_copy.next
it, it_copy = it.next, it_copy.next
it, it_copy = fake_head.next, fake_head_copy.next
while it:
if it.random:
node_map[it].random = node_map[it.random]
it, it_copy = it.next, it_copy.next
return fake_head_copy.next
梅花间竹解题思路:
第二种方法,梅花间竹,分3部走。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28def copyRandomList(self, head: 'Node') -> 'Node':
fake_head, fake_head_copy = Node(0), Node(0)
fake_head.next = head
# insert
it = fake_head.next
while it:
temp = it.next
it.next = Node(it.val)
it.next.next = temp
it = it.next.next
# copy random
it = fake_head.next
while it:
if it.random is not None:
it.next.random = it.random.next
it = it.next.next
# delete
it, it_copy = fake_head.next, fake_head_copy
while it:
temp = it.next
it.next = it.next.next
it_copy.next = temp
temp.next = None
it, it_copy = it.next, it_copy.next
return fake_head_copy.next
算法分析:
- 时间复杂度为
O(n),空间复杂度O(n)。 - 时间复杂度为
O(n),空间复杂度O(1)。

