You are given a string s and an integer k, a kduplicate removal consists of choosing k adjacent and equal letters from s and removing them, causing the left and the right side of the deleted substring to concatenate together.
We repeatedly make kduplicate removals on s until we no longer can.
Return the final string after all such duplicate removals have been made. It is guaranteed that the answer is unique.
Example 1:
<pre>Input: s = "abcd", k = 2
Output: "abcd"
Explanation: There's nothing to delete.</pre>
Example 2:
<pre>Input: s = "deeedbbcccbdaa", k = 3
Output: "aa"
Explanation: First delete "eee" and "ccc", get "ddbbbdaa"
Then delete "bbb", get "dddaa"
Finally delete "ddd", get "aa"</pre>
Example 3:
<pre>Input: s = "pbbcggttciiippooaais", k = 2
Output: "ps"
</pre>
defremoveDuplicates(self, s: str, k: int) -> str: stack, res = [], '' for i inrange(len(s)): if stack and stack[-1][0] == s[i] and stack[-1][1] == k - 1: while stack and stack[-1][0] == s[i]: stack.pop() else: if stack and stack[-1][0] == s[i]: stack.append((s[i], stack[-1][1] + 1)) else: stack.append((s[i], 1)) while stack: pair = stack.pop() res += pair[0] return res[::-1]
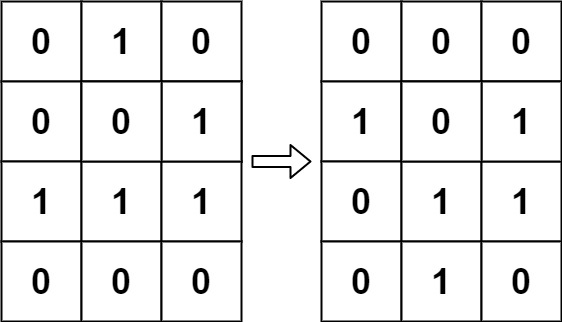
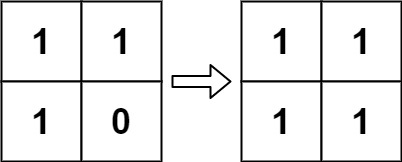
According to Wikipedia's article: "The Game of Life, also known simply as Life, is a cellular automaton devised by the British mathematician John Horton Conway in 1970."
The board is made up of an m x n grid of cells, where each cell has an initial state: live (represented by a 1) or dead (represented by a 0). Each cell interacts with its eight neighbors (horizontal, vertical, diagonal) using the following four rules (taken from the above Wikipedia article):
Any live cell with fewer than two live neighbors dies as if caused by under-population.
Any live cell with two or three live neighbors lives on to the next generation.
Any live cell with more than three live neighbors dies, as if by over-population.
Any dead cell with exactly three live neighbors becomes a live cell, as if by reproduction.
<span>The next state is created by applying the above rules simultaneously to every cell in the current state, where births and deaths occur simultaneously. Given the current state of the m x n grid board, return the next state.</span>
Could you solve it in-place? Remember that the board needs to be updated simultaneously: You cannot update some cells first and then use their updated values to update other cells.
In this question, we represent the board using a 2D array. In principle, the board is infinite, which would cause problems when the active area encroaches upon the border of the array (i.e., live cells reach the border). How would you address these problems?
defgameOfLife(self, board: List[List[int]]) -> None: res = [[0for _ inrange(len(board[0]))] for _ inrange(len(board))] for i inrange(len(board)): for j inrange(len(board[0])): live_neighbor_num = self.get_live_neighbor_num(board, i, j) if board[i][j] == 0and live_neighbor_num == 3: res[i][j] = 1 if board[i][j] == 1and live_neighbor_num in [2, 3]: res[i][j] = 1 board[:] = res
defget_live_neighbor_num(self, board, i, j): res = 0 for _dx, _dy in OFFSETS: x, y = i + _dx, j + _dy if0 <= x < len(board) and0 <= y < len(board[0]) and board[x][y] == 1: res += 1 return res
defgameOfLife2(self, board: List[List[int]]) -> None: # STATUS = {2: (0, 1), 3: (1, 0)} for i inrange(len(board)): for j inrange(len(board[0])): live_neighbor_num = self.get_live_neighbor_num2(board, i, j) if board[i][j] == 0and live_neighbor_num == 3: board[i][j] = 2 if board[i][j] == 1and live_neighbor_num notin [2, 3]: board[i][j] = 3 for i inrange(len(board)): for j inrange(len(board[0])): if board[i][j] == 2: board[i][j] = 1 if board[i][j] == 3: board[i][j] = 0
defget_live_neighbor_num2(self, board, i, j): res = 0 for _dx, _dy in OFFSETS: x, y = i + _dx, j + _dy if0 <= x < len(board) and0 <= y < len(board[0]) and board[x][y] in [1, 3]: res += 1 return res
Design a hit counter which counts the number of hits received in the past 5 minutes (i.e., the past 300 seconds).
Your system should accept a timestamp parameter (in seconds granularity), and you may assume that calls are being made to the system in chronological order (i.e., timestamp is monotonically increasing). Several hits may arrive roughly at the same time.
Implement the HitCounter class:
HitCounter() Initializes the object of the hit counter system.
void hit(int timestamp) Records a hit that happened at timestamp (in seconds). Several hits may happen at the same timestamp.
int getHits(int timestamp) Returns the number of hits in the past 5 minutes from timestamp (i.e., the past 300 seconds).
Explanation
HitCounter hitCounter = new HitCounter();
hitCounter.hit(1); // hit at timestamp 1.
hitCounter.hit(2); // hit at timestamp 2.
hitCounter.hit(3); // hit at timestamp 3.
hitCounter.getHits(4); // get hits at timestamp 4, return 3.
hitCounter.hit(300); // hit at timestamp 300.
hitCounter.getHits(300); // get hits at timestamp 300, return 4.
hitCounter.getHits(301); // get hits at timestamp 301, return 3.
</pre>
Constraints:
1 <= timestamp <= 2 * 10<sup>9</sup>
All the calls are being made to the system in chronological order (i.e., timestamp is monotonically increasing).
At most 300 calls will be made to hit and getHits.
Follow up: What if the number of hits per second could be huge? Does your design scale?
Given an array of strings words and an integer k, return thekmost frequent strings.
Return the answer sorted by the frequency from highest to lowest. Sort the words with the same frequency by their lexicographical order.
Example 1:
<pre>Input: words = ["i","love","leetcode","i","love","coding"], k = 2
Output: ["i","love"]
Explanation: "i" and "love" are the two most frequent words.
Note that "i" comes before "love" due to a lower alphabetical order.
</pre>
Example 2:
<pre>Input: words = ["the","day","is","sunny","the","the","the","sunny","is","is"], k = 4
Output: ["the","is","sunny","day"]
Explanation: "the", "is", "sunny" and "day" are the four most frequent words, with the number of occurrence being 4, 3, 2 and 1 respectively.
</pre>
Constraints:
1 <= words.length <= 500
1 <= words[i] <= 10
words[i] consists of lowercase English letters.
k is in the range [1, The number of **unique** words[i]]
Follow-up: Could you solve it in O(n log(k)) time and O(n) extra space?
deftopKFrequent(self, words: List[str], k: int) -> List[str]: freq_dict = collections.Counter(words) li = [(freq, word) for word, freq in freq_dict.items()] li.sort(key=lambda x : (-x[0], x[1])) return [pair[1] for pair in li[:k]]
Roman numerals are represented by seven different symbols: I, V, X, L, C, D and M.
<pre>SymbolValue
I 1
V 5
X 10
L 50
C 100
D 500
M 1000</pre>
For example, 2 is written as II in Roman numeral, just two one's added together. 12 is written as XII, which is simply X + II. The number 27 is written as XXVII, which is XX + V + II.
Roman numerals are usually written largest to smallest from left to right. However, the numeral for four is not IIII. Instead, the number four is written as IV. Because the one is before the five we subtract it making four. The same principle applies to the number nine, which is written as IX. There are six instances where subtraction is used:
I can be placed before V (5) and X (10) to make 4 and 9.
X can be placed before L (50) and C (100) to make 40 and 90.
C can be placed before D (500) and M (1000) to make 400 and 900.
Given an integer, convert it to a roman numeral.
Example 1:
<pre>Input: num = 3
Output: "III"
Explanation: 3 is represented as 3 ones.
</pre>
Example 2:
<pre>Input: num = 58
Output: "LVIII"
Explanation: L = 50, V = 5, III = 3.
</pre>
Example 3:
<pre>Input: num = 1994
Output: "MCMXCIV"
Explanation: M = 1000, CM = 900, XC = 90 and IV = 4.
</pre>
defintToRoman(self, num: int) -> str: INT_TO_ROMAN = [(1000, 'M'), (900, 'CM'), (500, 'D'), (400, 'CD'), (100, 'C'), (90, 'XC'), (50, 'L'), (40, 'XL'), (10, 'X'), (9, 'IX'), (5, 'V'), (4, 'IV'), (1, 'I')] res = '' for n, symbol in INT_TO_ROMAN: count, num = num // n, num % n res += symbol * count return res