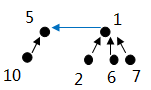
defdfs(self, graph, start, visited, res): if start in visited: return visited.add(start) res.append(start) for node in graph[start]: self.dfs(graph, visited, node, res)
字符型DFS
注意事项:
输入值为空的情况或空节点
求得解以后复制path到result中
终止条件记得return
每次递归完恢复输入图或中间结果path的状态,递归式用i + 1
Python代码:
1 2 3 4 5 6
defdfs(self, input, start, endIndex, path, result): if start == endIndex: result.append(list(path)) return for i in <func>(input[start]): self.dfs(input, i + 1, endIndex , path + input[i], result)
与记忆性搜索的模板类似,有时需要和它一起用,见LeetCode 241 Different Ways to Add Parentheses
Python代码:
1 2 3 4 5 6 7 8 9
defdfs(self, input): if <终止条件>: return [] # remember to use list res = [] for i in range(len(input)): left_res = self.dfs(input[:i]) right_res = self.dfs(input[i + 1:]) res += [<calculate results> for _l in left_res for _r in right_res] return res
publicintmaxProfit(int[] prices){ int max = 0; for(int i=0;i<prices.length;i++){ int p = maxProfitSingle(Arrays.copyOfRange(prices,0, i+1)) + maxProfitSingle(Arrays.copyOfRange(prices,i, prices.length)); if(max<p) max = p; } return max; }
classUnionFind{ int count; // # of connected components int[] parent; int[] rank;
publicUnionFind(char[][] grid){ // for problem 200 count = 0; int m = grid.length; int n = grid[0].length; parent = newint[m * n]; rank = newint[m * n]; for (int i = 0; i < m; ++i) { for (int j = 0; j < n; ++j) { if (grid[i][j] == '1') { parent[i * n + j] = i * n + j; ++count; } rank[i * n + j] = 0; } } }
// union point x and y with rank publicvoidunion(int x, int y){ int rootx = find(x); int rooty = find(y); if (rootx != rooty) { if (rank[rootx] > rank[rooty]) { parent[rooty] = rootx; } elseif (rank[rootx] < rank[rooty]) { parent[rootx] = rooty; } else { parent[rooty] = rootx; rank[rootx] += 1; } --count; } }
Given a 2d grid map of '1's (land) and '0's (water), count the number of islands. An island is surrounded by water and is formed by connecting adjacent lands horizontally or vertically. You may assume all four edges of the grid are all surrounded by water.
OFFSETS = [(1, 0), (-1, 0), (0, 1), (0, -1)] classSolution: defnumIslands(self, grid: List[List[str]]) -> int: ifnot grid: return0 count = 0 for i in range(len(grid)): for j in range(len(grid[0])): if grid[i][j] == '1': self.bfs(grid, i, j) count += 1 return count
defbfs(self, nums, i, j): queue = deque([(i, j)]) nums[i][j] = 'X' while queue: island = queue.popleft() for dx, dy in OFFSETS: x, y = island[0] + dx, island[1] + dy if x < 0or x >= len(nums) or y < 0or y >= len(nums[0]) or nums[x][y] in ['0', 'X']: continue queue.append((x, y)) nums[x][y] = 'X'
publicvoiddfs(char[][] grid, int a, int b){ if(!isValid(grid,a,b)) return; grid[a][b] = 'x'; dfs(grid, a+1, b); dfs(grid, a-1, b); dfs(grid, a, b+1); dfs(grid, a, b-1); }
publicbooleanisValid(char[][] grid, int x, int y){ if(x<0||x>=grid.length||y<0||y>=grid[0].length||grid[x][y]!='1') returnfalse; returntrue; }
classUnionFind{ int count; // # of connected components int[] parent; int[] rank;
publicUnionFind(char[][] grid){ // for problem 200 count = 0; int m = grid.length; int n = grid[0].length; parent = newint[m * n]; rank = newint[m * n]; for (int i = 0; i < m; ++i) { for (int j = 0; j < n; ++j) { if (grid[i][j] == '1') { parent[i * n + j] = i * n + j; ++count; } rank[i * n + j] = 0; } } }
For this problem, a path is defined as any sequence of nodes from some starting node to any node in the tree along the parent-child connections. The path must contain at least one node and does not need to go through the root.