<div>
Given a 2D matrix matrix, handle multiple queries of the following type:
- Calculate the sum of the elements of
matrixinside the rectangle defined by its upper left corner(row1, col1)and lower right corner(row2, col2).
Implement the NumMatrix class:
NumMatrix(int[][] matrix)Initializes the object with the integer matrixmatrix.int sumRegion(int row1, int col1, int row2, int col2)Returns the sum of the elements ofmatrixinside the rectangle defined by its upper left corner(row1, col1)and lower right corner(row2, col2).
Example 1:
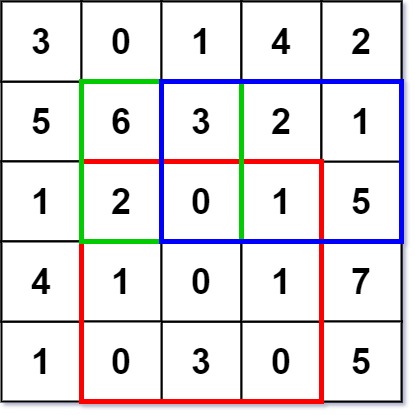
<pre>Input ["NumMatrix", "sumRegion", "sumRegion", "sumRegion"] [[[[3, 0, 1, 4, 2], [5, 6, 3, 2, 1], [1, 2, 0, 1, 5], [4, 1, 0, 1, 7], [1, 0, 3, 0, 5]]], [2, 1, 4, 3], [1, 1, 2, 2], [1, 2, 2, 4]] Output [null, 8, 11, 12]
Explanation NumMatrix numMatrix = new NumMatrix([[3, 0, 1, 4, 2], [5, 6, 3, 2, 1], [1, 2, 0, 1, 5], [4, 1, 0, 1, 7], [1, 0, 3, 0, 5]]); numMatrix.sumRegion(2, 1, 4, 3); // return 8 (i.e sum of the red rectangle) numMatrix.sumRegion(1, 1, 2, 2); // return 11 (i.e sum of the green rectangle) numMatrix.sumRegion(1, 2, 2, 4); // return 12 (i.e sum of the blue rectangle) </pre>
Constraints:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 200-10<sup>5</sup> <= matrix[i][j] <= 10<sup>5</sup>0 <= row1 <= row2 < m0 <= col1 <= col2 < n- At most
10<sup>4</sup>calls will be made tosumRegion.
</div>
题目大意:
求子矩阵和
解题思路:
计算presum公式:
1
dp[i][j] = matrix[i-1][j-1] + dp[i-1][j] + dp[i][j] - dp[i-1][j-1]
计算子矩阵公式:
1
res = presum[x][y] - left - top + diag
解题步骤:
N/A
注意事项:
- dp有左上边界,计算子矩阵注意dp和输入差1
Python代码:
1
2
3
4
5
6
7
8
9
10class NumMatrix(TestCases):
def __init__(self, matrix: List[List[int]]):
self.dp = [[0 for _ in range(len(matrix[0]) + 1)] for _ in range(len(matrix) + 1)]
for i in range(1, len(self.dp)):
for j in range(1, len(self.dp[0])):
self.dp[i][j] = matrix[i - 1][j - 1] + self.dp[i - 1][j] + self.dp[i][j - 1] - self.dp[i - 1][j - 1]
def sumRegion(self, row1: int, col1: int, row2: int, col2: int) -> int:
return self.dp[row2 + 1][col2 + 1] - self.dp[row2 + 1][col1] - self.dp[row1][col2 + 1] + self.dp[row1][col1]
算法分析:
时间复杂度为O(1),空间复杂度O(nm)