


Given the
root of a binary tree, calculate the vertical order traversal of the binary tree.For each node at position
(row, col), its left and right children will be at positions (row + 1, col - 1) and (row + 1, col + 1) respectively. The root of the tree is at (0, 0).The vertical order traversal of a binary tree is a list of top-to-bottom orderings for each column index starting from the leftmost column and ending on the rightmost column. There may be multiple nodes in the same row and same column. In such a case, sort these nodes by their values.
Return the vertical order traversal of the binary tree.
Example 1:
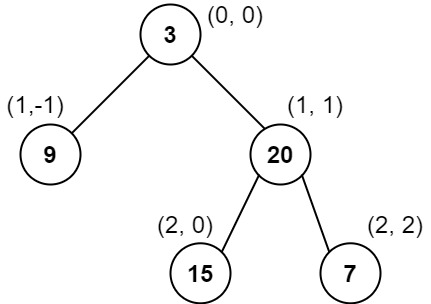
Input: root = [3,9,20,null,null,15,7]
Output: [[9],[3,15],[20],[7]]
Explanation:
Column -1: Only node 9 is in this column.
Column 0: Nodes 3 and 15 are in this column in that order from top to bottom.
Column 1: Only node 20 is in this column.
Column 2: Only node 7 is in this column.
Example 2:
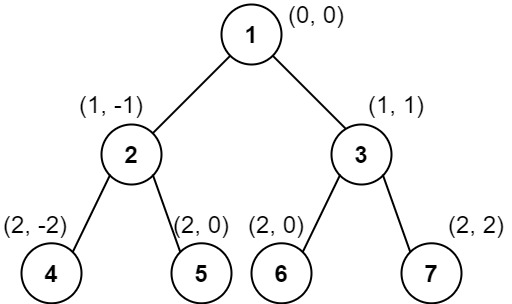
Input: root = [1,2,3,4,5,6,7]
Output: [[4],[2],[1,5,6],[3],[7]]
Explanation:
Column -2: Only node 4 is in this column.
Column -1: Only node 2 is in this column.
Column 0: Nodes 1, 5, and 6 are in this column.
1 is at the top, so it comes first.
5 and 6 are at the same position (2, 0), so we order them by their value, 5 before 6.
Column 1: Only node 3 is in this column.
Column 2: Only node 7 is in this column.
Example 3:
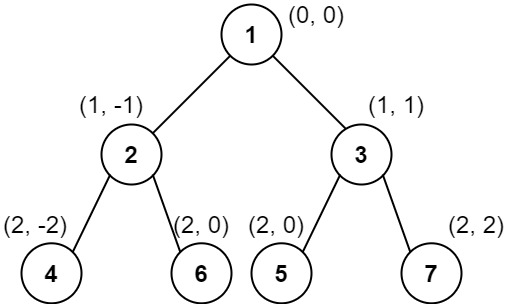
Input: root = [1,2,3,4,6,5,7]
Output: [[4],[2],[1,5,6],[3],[7]]
Explanation:
This case is the exact same as example 2, but with nodes 5 and 6 swapped.
Note that the solution remains the same since 5 and 6 are in the same location and should be ordered by their values.
Constraints:
The number of nodes in the tree is in the range
[1, 1000].
0 <= Node.val <= 1000题目大意:
按列顺序打印二叉树,若列号同,同一行的节点按值排序
解题思路:
与LeetCode 314 Binary Tree Vertical Order Traversal类似,用BFS
LeetCode 314 Binary Tree Vertical Order Traversal 同一列,从上到下,从左到右排序
LeetCode 987 Vertical Order Traversal of a Binary Tree 同一列,从上到下,同一行值从小到大排序
解题步骤:
N/A
注意事项:
与LeetCode 314实现的区别
- 一开始以为同一列的同一行的节点在queue是一个紧接一个出列。但同一行节点可能先出列col=3, col=4, col=3。而且同一列同一行的节点有多个,不止两个。所以将row_id也加入到queue节点和map中
- 遍历结果时,map中的value排序**, value是先row_id再node.val,所以直接可以排序,最后直接取出第二维度
Python代码:
1 | def verticalTraversal(self, root: TreeNode) -> List[List[int]]: |
算法分析:
时间复杂度为O(n),空间复杂度O(1),稍大于O(n), 因为同一列同一行节点要排序
