You are given an array of words where each word consists of lowercase English letters.
word<sub>A</sub> is a predecessor of word<sub>B</sub> if and only if we can insert exactly one letter anywhere in word<sub>A</sub>without changing the order of the other characters to make it equal to word<sub>B</sub>.
For example, "abc" is a predecessor of "ab<u>a</u>c", while "cba" is not a predecessor of "bcad".
A word chainis a sequence of words [word<sub>1</sub>, word<sub>2</sub>, ..., word<sub>k</sub>] with k >= 1, where word<sub>1</sub> is a predecessor of word<sub>2</sub>, word<sub>2</sub> is a predecessor of word<sub>3</sub>, and so on. A single word is trivially a word chain with k == 1.
Return the length of the longest possible word chain with words chosen from the given list ofwords.
Example 1:
<pre>Input: words = ["a","b","ba","bca","bda","bdca"]
Output: 4
Explanation: One of the longest word chains is ["a","<u>b</u>a","b<u>d</u>a","bd<u>c</u>a"].
</pre>
Example 2:
<pre>Input: words = ["xbc","pcxbcf","xb","cxbc","pcxbc"]
Output: 5
Explanation: All the words can be put in a word chain ["xb", "xb<u>c</u>", "<u>c</u>xbc", "<u>p</u>cxbc", "pcxbc<u>f</u>"].
</pre>
Example 3:
<pre>Input: words = ["abcd","dbqca"]
Output: 1
Explanation: The trivial word chain ["abcd"] is one of the longest word chains.
["abcd","dbqca"] is not a valid word chain because the ordering of the letters is changed.
</pre>
Constraints:
1 <= words.length <= 1000
1 <= words[i].length <= 16
words[i] only consists of lowercase English letters.
</div>
Problem Overview
Get longgest one-character transformation in the given list
Thinking Process
This problem is similar to Word Break (reversed to get neighbors) but it is a multi-source longest path problem.
Steps
Loop through each word
BFS from each word and get the max distance
Get the max of distance
Notes
max_dis = 1 by default in BFS
To improve the complexity, make the distance map global so that the distance of each node will be calculated once.
To do that, sort the list from longest to shortest and make sure the it is greedy to get the max distance
defbfs(self, word, word_dict, distance): queue = deque([word]) visited = {word} if word in distance: # remember return distance[word] distance[word] = 1 max_dis = 1 while queue: node = queue.popleft() for neighbor inself.get_neighbors(node, word_dict): if neighbor in visited: continue queue.append(neighbor) visited.add(neighbor) distance[neighbor] = distance[node] + 1 max_dis = max(max_dis, distance[neighbor]) return max_dis
defget_neighbors(self, word, word_dict): res = [] for i inrange(len(word)): new_word = word[:i] + word[i + 1:] if new_word in word_dict: res.append(new_word) return res
Analysis
Though there is a loop and bfs like n^2, actually it is a traversal in a graph. n * L (n is # of nodes, L is max of path
single-source) is the num of edges. Another L is to get neighbors.
Time complexity<code>O(nlogn + n*L<sup>2</sup>)</code>, Space complexityO(n).
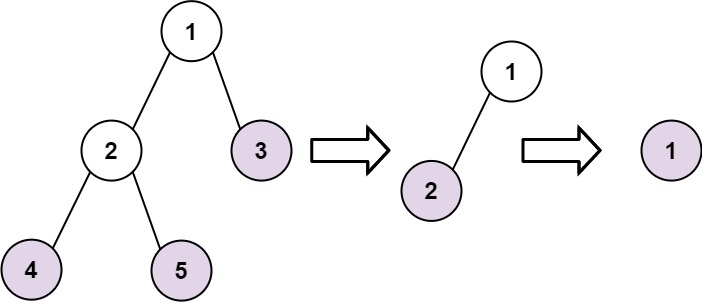
Given the root of a binary tree, collect a tree's nodes as if you were doing this:
Collect all the leaf nodes.
Remove all the leaf nodes.
Repeat until the tree is empty.
Example 1:
<pre>Input: root = [1,2,3,4,5]
Output: [[4,5,3],[2],[1]]
Explanation:
[[3,5,4],[2],[1]] and [[3,4,5],[2],[1]] are also considered correct answers since per each level it does not matter the order on which elements are returned.
</pre>
Example 2:
<pre>Input: root = [1]
Output: [[1]]
</pre>
Constraints:
The number of nodes in the tree is in the range [1, 100].
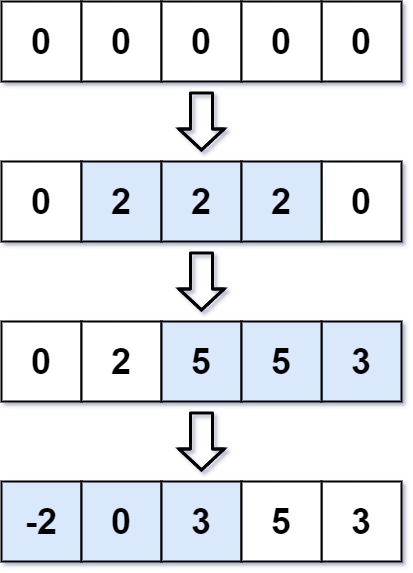
You are given an integer length and an array updates where updates[i] = [startIdx<sub>i</sub>, endIdx<sub>i</sub>, inc<sub>i</sub>].
You have an array arr of length length with all zeros, and you have some operation to apply on arr. In the i<sup>th</sup> operation, you should increment all the elements arr[startIdx<sub>i</sub>], arr[startIdx<sub>i</sub> + 1], ..., arr[endIdx<sub>i</sub>] by inc<sub>i</sub>.
defgetModifiedArray(self, length: int, updates: List[List[int]]) -> List[int]: res = [0] * length for li in updates: res[li[0]] += li[2] # remember += not = if li[1] + 1 < len(res): # remember not len(li) res[li[1] + 1] += -li[2] # remember += not = for i inrange(1, len(res)): res[i] += res[i - 1] return res
You are given an array of variable pairs equations and an array of real numbers values, where equations[i] = [A<sub>i</sub>, B<sub>i</sub>] and values[i] represent the equation A<sub>i</sub> / B<sub>i</sub> = values[i]. Each A<sub>i</sub> or B<sub>i</sub> is a string that represents a single variable.
You are also given some queries, where queries[j] = [C<sub>j</sub>, D<sub>j</sub>] represents the j<sup>th</sup> query where you must find the answer for C<sub>j</sub> / D<sub>j</sub> = ?.
Return the answers to all queries. If a single answer cannot be determined, return -1.0.
Note: The input is always valid. You may assume that evaluating the queries will not result in division by zero and that there is no contradiction.
Example 1:
<pre>Input: equations = [["a","b"],["b","c"]], values = [2.0,3.0], queries = [["a","c"],["b","a"],["a","e"],["a","a"],["x","x"]]
Output: [6.00000,0.50000,-1.00000,1.00000,-1.00000]
Explanation:
Given: a / b = 2.0, b / c = 3.0
queries are: a / c = ?, b / a = ?, a / e = ?, a / a = ?, x / x = ?
return: [6.0, 0.5, -1.0, 1.0, -1.0 ]
</pre>
defcalcEquation(self, equations: List[List[str]], values: List[float], queries: List[List[str]]) -> List[float]: graph = collections.defaultdict(list) for i, li inenumerate(equations): graph[li[0]].append((li[1], values[i])) graph[li[1]].append((li[0], 1 / values[i])) # remember it is an undirected graph res = [] for query in queries: if query[0] notin graph or query[1] notin graph: res.append(-1.0) elif query[0] in graph and query[0] == query[1]: res.append(1.0) else: val = self.bfs(graph, query) res.append(val) return res
defbfs(self, graph, query): queue = collections.deque([(query[0], 1)]) visited = set([queue[0]]) while queue: node, parent_val = queue.popleft() if node == query[1]: return parent_val for neighbor, val in graph[node]: if neighbor in visited: continue queue.append((neighbor, parent_val * val)) visited.add(neighbor) return -1# remember