<div>
Convert a Binary Search Tree to a sorted Circular Doubly-Linked List in place.
You can think of the left and right pointers as synonymous to the predecessor and successor pointers in a doubly-linked list. For a circular doubly linked list, the predecessor of the first element is the last element, and the successor of the last element is the first element.
We want to do the transformation in place. After the transformation, the left pointer of the tree node should point to its predecessor, and the right pointer should point to its successor. You should return the pointer to the smallest element of the linked list.
Example 1:
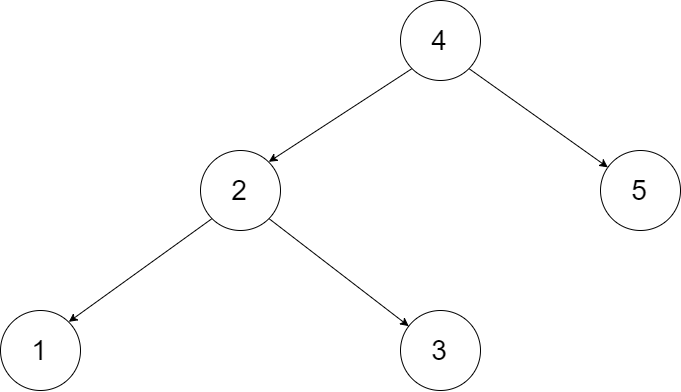
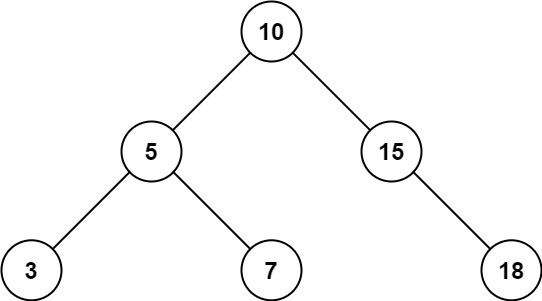
<pre>Input: root = [4,2,5,1,3]
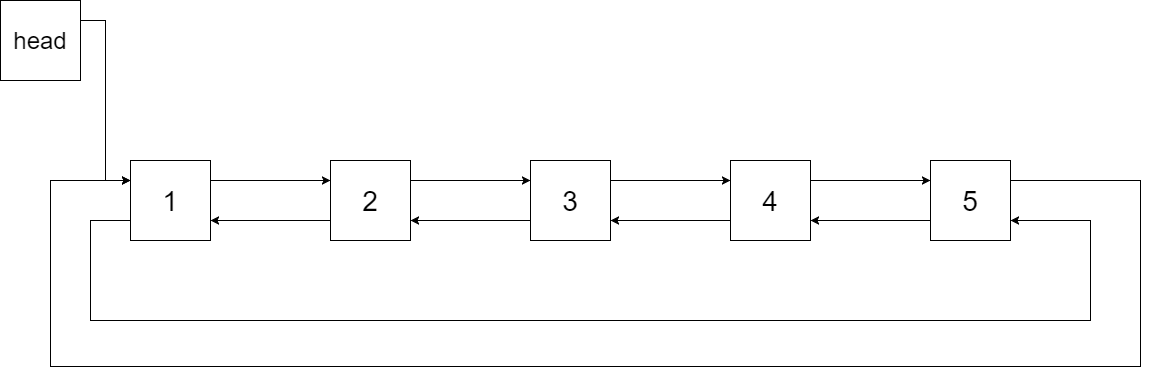 Output: [1,2,3,4,5]
Output: [1,2,3,4,5]
Explanation: The figure below shows the transformed BST. The solid line indicates the successor relationship, while the dashed line means the predecessor relationship.
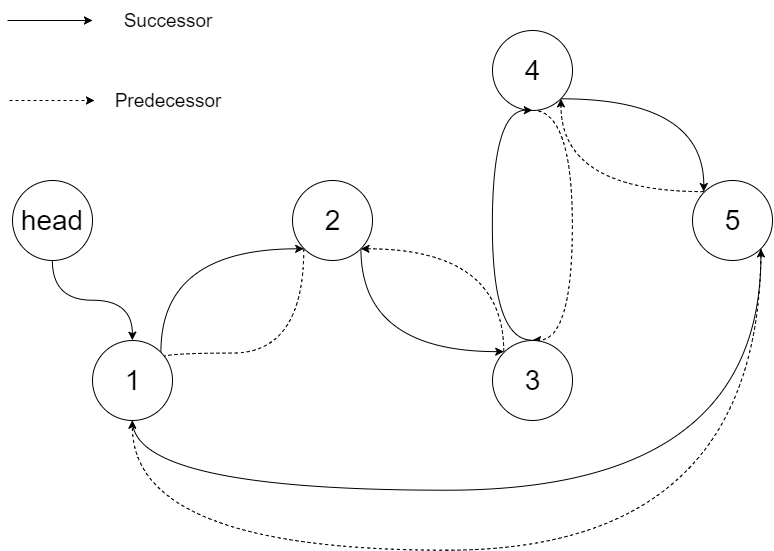 </pre>
</pre>
Example 2:
<pre>Input: root = [2,1,3] Output: [1,2,3] </pre>
Constraints:
- The number of nodes in the tree is in the range
[0, 2000]. -1000 <= Node.val <= 1000- All the values of the tree are unique.
</div>
题目大意:
将二叉树变成双向链表,left为父节点,right为儿子节点
解题思路:
类似于LeetCode 114 Flatten Binary Tree to Linked List,先假设左右儿子,已经是双向LL,下面就是将root这个节点插入到两个LL之间其将它们首尾相连
解题步骤:
N/A
注意事项:
- 要将左右儿子节点的LL,首尾相连。首尾节点获得要在if语句前,因为右儿子的left会连到root,就找不到它的尾部。首尾相连要发生在最后。
Python代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def treeToDoublyList(self, root: 'Node') -> 'Node':
if not root:
return None
if not root.left and not root.right:
root.left, root.right = root, root
return root
left_head = self.treeToDoublyList(root.left)
right_head = self.treeToDoublyList(root.right)
# remember this part and order, can't be placed after ifs
new_head = left_head if left_head else root
new_tail = right_head.left if right_head else root
if left_head:
left_head.left.right, root.left = root, left_head.left
if right_head:
root.right, right_head.left = right_head, root
new_head.left, new_tail.right = new_tail, new_head
return new_head
算法分析:
时间复杂度为O(n),空间复杂度O(1)