


We have
n jobs, where every job is scheduled to be done from startTime[i] to endTime[i], obtaining a profit of profit[i].You’re given the
startTime, endTime and profit arrays, return the maximum profit you can take such that there are no two jobs in the subset with overlapping time range.If you choose a job that ends at time
X you will be able to start another job that starts at time X.Example 1:
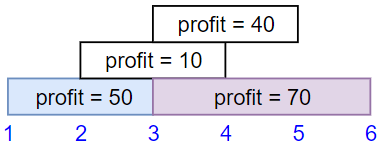
Input: startTime = [1,2,3,3], endTime = [3,4,5,6], profit = [50,10,40,70]
Output: 120
Explanation: The subset chosen is the first and fourth job.
Time range [1-3]+[3-6] , we get profit of 120 = 50 + 70.
Example 2:
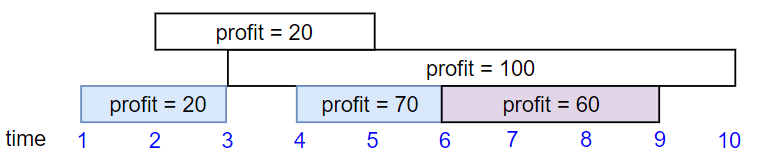
Input: startTime = [1,2,3,4,6], endTime = [3,5,10,6,9], profit = [20,20,100,70,60]
Output: 150
Explanation: The subset chosen is the first, fourth and fifth job.
Profit obtained 150 = 20 + 70 + 60.
Example 3:

Input: startTime = [1,1,1], endTime = [2,3,4], profit = [5,6,4]
Output: 6
Constraints:
`1 <= startTime.length == endTime.length == profit.length <= 5 104
*1 <= startTime[i] < endTime[i] <= 109*1 <= profit[i] <= 104`算法思路:
DP + 排序
一开始以为类似于meeting rooms II,所以用heap,但只能计算conflicts不能计算profits,但排序思想有用。
求最值问题第一时间考虑用DP,所以考虑以第i-1个job为结尾的最大利润:
dp[i] = max -> dp[j] + profits[i-1]), 第i个job的startTime[i-1] >= endTime[j], 第j个job与第i个job没有conflicts
-> dp[j] 第j个job与第i个job有conflicts
复杂度为O(n^2)
写出递归式后,求startTime >= endTime其实就是按endTime排序,这样有助于搜索这个条件. 这里有个难点是要加强命题至累计利润,因为正如Cooldown股票题一样,dp[j]不应该是以job j为结尾的最大利润,而应该是前j个job的最大利润,这些job不一定都是相邻
加强命题dp[i]是累计利润,也就是并不需要计算所有dp[j…i]的值(第一式子),公式变成
dp[i] = max -> dp[j] + profits[i-1]), j = start[i-1]对应的Endtime下标, 第j个job与第i个job没有conflicts
-> dp[j] 第j个job与第i个job有conflicts
要找出这个j,就对刚才排序了的endtime数组用bisect找下标。类似于LIS, 复杂度为O(nlogn)
注意事项:
- bisect的使用求大于startTime的endTime下标,此下标j减一正是所求,但dp和数组中下标转换是差1,所以dp[j - 1 + 1]是前值的DP值。
- 加强命题至累计利润dp[i], 见line 9 - 10
Python代码:
1 | def jobScheduling(self, startTime: List[int], endTime: List[int], profit: List[int]) -> int: |
算法分析:
时间复杂度为O(nlogn),空间复杂度O(n)
