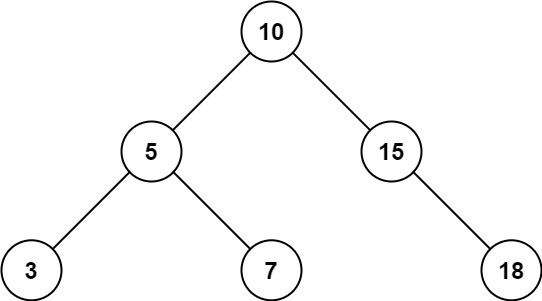
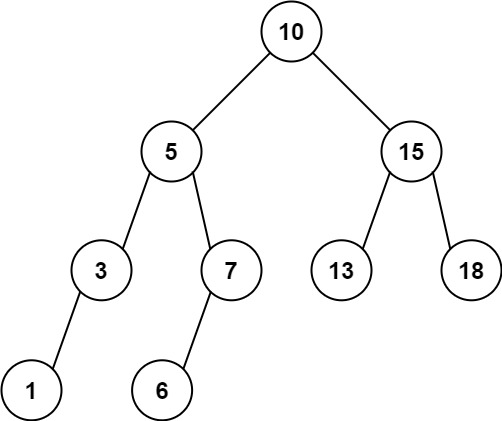
Given the root node of a binary search tree and two integers low and high, return the sum of values of all nodes with a value in the inclusive range[low, high].
Example 1:
Input: root = [10,5,15,3,7,null,18], low = 7, high = 15 Output: 32 Explanation: Nodes 7, 10, and 15 are in the range [7, 15]. 7 + 10 + 15 = 32.
Example 2:
Input: root = [10,5,15,3,7,13,18,1,null,6], low = 6, high = 10 Output: 23 Explanation: Nodes 6, 7, and 10 are in the range [6, 10]. 6 + 7 + 10 = 23.
Constraints:
The number of nodes in the tree is in the range `[1, 2 104].
*1 <= Node.val <= 105*1 <= low <= high <= 105* AllNode.val` are unique.
Design a HashMap without using any built-in hash table libraries.
Implement the MyHashMap class:
MyHashMap() initializes the object with an empty map.
void put(int key, int value) inserts a (key, value) pair into the HashMap. If the key already exists in the map, update the corresponding value. int get(int key) returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key.
void remove(key) removes the key and its corresponding value if the map contains the mapping for the key.
Explanation MyHashMap myHashMap = new MyHashMap(); myHashMap.put(1, 1); // The map is now [[1,1]] myHashMap.put(2, 2); // The map is now [[1,1], [2,2]] myHashMap.get(1); // return 1, The map is now [[1,1], [2,2]] myHashMap.get(3); // return -1 (i.e., not found), The map is now [[1,1], [2,2]] myHashMap.put(2, 1); // The map is now [[1,1], [2,1]] (i.e., update the existing value) myHashMap.get(2); // return 1, The map is now [[1,1], [2,1]] myHashMap.remove(2); // remove the mapping for 2, The map is now [[1,1]] myHashMap.get(2); // return -1 (i.e., not found), The map is now [[1,1]]
Constraints:
0 <= key, value <= 10<sup>6</sup> At most 10<sup>4</sup> calls will be made to put, get, and remove.
题目大意:
设计HashMap
LL解题思路(推荐):
大学学到的方法,用Array实现,将key mod prime num找到index插入。难点在于冲突处理,这里用chaining方法,也就是LL
def__init__(self): self.key_space = 997 self.buckets = [[] for _ in range(self.key_space)]
defput(self, key: int, value: int) -> None: index = key % self.key_space for i, [_key, _val] in enumerate(self.buckets[index]): if _key == key: self.buckets[index][i] = [key, value] return self.buckets[index].append([key, value])
defget(self, key: int) -> int: index = key % self.key_space for _key, _val in self.buckets[index]: if _key == key: return _val return-1
defremove(self, key: int) -> None: index = key % self.key_space for i, [_key, _val] in enumerate(self.buckets[index]): if _key == key: self.buckets[index].pop(i) return
Input - (“mon 10:00 am”, mon 11:00 am) Output - [11005, 11010, 11015…11100] Output starts with 1 if the day is monday, 2 if tuesday and so on till 7 for sunday Append 5 min interval times to that till the end time So here it is 10:05 as first case, so its written as 11005 2nd is 10:10 so its written as 11010
defget_intervals(self, start, end) -> List: start_time = Time(start) end_time = Time(end) if start_time.min % 5 > 0: start_time.add(5 - start_time.min % 5) end_time.add(1) res = [] while start_time < end_time: res.append(start_time.get_numeric()) start_time.add(5) return res
classTime:
def__init__(self, time): parts = time.split(' ') day = DAY_DICT[parts[0]] time_parts = parts[1].split(':') hour = int(time_parts[0]) % 12 + (0if parts[2] == 'am'else12) # remember paren (0 ...12), and % 12 self.day = day self.hour = hour self.min = int(time_parts[1])
def__lt__(self, other): if self.day < other.day or (self.day == other.day and self.hour < other.hour) or \ (self.day == other.day and self.hour == other.hour and self.min < other.min): returnTrue else: returnFalse
Implement a basic calculator to evaluate a simple expression string.
The expression string contains only non-negative integers, '+', '-', '*', '/' operators, and open '(' and closing parentheses ')'. The integer division should truncate toward zero.
You may assume that the given expression is always valid. All intermediate results will be in the range of [-2<sup>31</sup>, 2<sup>31</sup> - 1].
Note: You are not allowed to use any built-in function which evaluates strings as mathematical expressions, such as eval().
Example 1:
Input: s = “1+1” Output: 2
Example 2:
Input: s = “6-4/2” Output: 4
Example 3:
Input: s = “2(5+52)/3+(6/2+8)” Output: 21
Constraints:
1 <= s <= 10<sup>4</sup>s consists of digits, '+', '-', '*', '/', '(', and ')'. s is a *valid expression.
Design a data structure to store the strings’ count with the ability to return the strings with minimum and maximum counts.
Implement the AllOne class:
AllOne() Initializes the object of the data structure.
inc(String key) Increments the count of the string key by 1. If key does not exist in the data structure, insert it with count 1. dec(String key) Decrements the count of the string key by 1. If the count of key is 0 after the decrement, remove it from the data structure. It is guaranteed that key exists in the data structure before the decrement.
getMaxKey() Returns one of the keys with the maximal count. If no element exists, return an empty string "". getMinKey() Returns one of the keys with the minimum count. If no element exists, return an empty string "".
Constraints:1 <= key.length <= 10 key consists of lowercase English letters.
It is guaranteed that for each call to dec, key is existing in the data structure. At most `5 104calls will be made toinc,dec,getMaxKey, andgetMinKey`.
count -= 1 if count in self.freq_to_node and key in self.freq_to_node[count].key_set: self.freq_to_node[count].key_set.remove(key) if len(self.freq_to_node[count].key_set) == 0: self.remove_node(self.freq_to_node[count]) self.freq_to_node.pop(count) # remember
count += 1 if count in self.freq_to_node and key in self.freq_to_node[count].key_set: self.freq_to_node[count].key_set.remove(key) if len(self.freq_to_node[count].key_set) == 0: self.remove_node(self.freq_to_node[count]) self.freq_to_node.pop(count)